
How to Prevent Search Engines from Indexing Pages and Files on Your Website
Last Updated: May 28, 2025
Search engines are essential for driving traffic to your site, but sometimes you may want to keep certain pages or files hidden from search results. Whether you're working on a private area of your website, testing content or storing sensitive documents, it's important to understand how to control which parts of your site are visible to search engines. This post explains how to use the robots.txt file to manage crawler access and prevent specific content from being indexed.
Search engine bots, also known as crawlers or spiders, are constantly browsing the internet, following links and indexing content for search results. While this process generally helps your website gain visibility and attract visitors, there are scenarios where you'd want to prevent specific pages or files from being indexed.
By default, once your website is live and linked to from other pages, it becomes eligible for crawling and indexing. Search engines like Google, Bing, and others will start visiting your pages and include them in their search results if they're not blocked. But what if you're developing a site in private? Or have internal files you don't want publicly visible? That's where the robots.txt file comes into play.
The robots.txt file is a simple but powerful tool that lets you control which bots can access your site and what parts of your site they can see. It helps improve site security, conserve server resources, and control your search engine presence. Let's walk through what it is, how to create one, and how to use it properly.
What Is a robots.txt File?
The robots.txt file is a text-based configuration file placed at the root of your website. Its purpose is to give instructions to search engine bots about which parts of your site should not be accessed or indexed. It uses a set of directives such as User-agent and Disallow to specify these rules.
For example, if you want to stop all bots from accessing a specific directory, you can easily list it in this file. Major search engines like Google and Bing respect the instructions in robots.txt, although malicious bots and some scrapers or even less popular search engines may ignore it.
Why Use robots.txt?
There are several legitimate reasons to block indexing of certain content:
- Private content: Pages meant for internal or personal use only.
- Under-construction pages: You don't want unfinished work being indexed and appearing in search results.
- Duplicate content: You want to avoid penalties for having the same content across multiple URLs.
- Resource directories: Blocking scripts, style files or image folders to reduce crawl budget usage.
- Sensitive files: Such as PDF reports, form handler scripts or log files.
How to Create a robots.txt File
Creating a robots.txt file is straightforward. Follow these steps:
Step 1: Open Your Text Editor
Open a plain text editor such as Notepad on Windows or TextEdit on Mac. Avoid using word processors like Microsoft Word because they may insert formatting that makes the file unreadable to bots.
Step 2: Add Your Rules
Insert the appropriate directives to define how bots should interact with your site. We'll go over rule examples shortly.
Step 3: Save the File
Save the file as robots.txt with no additional extensions (name of the file is robots and the extension is .txt).
Step 4: Upload to Your Web Server
Place the file in the root directory of your domain. For example:
https://www.example.com/robots.txt
This location is critical because bots will look specifically for it when deciding how to crawl your site, that is, if they are "honest" bots that honor your crawling instructions.
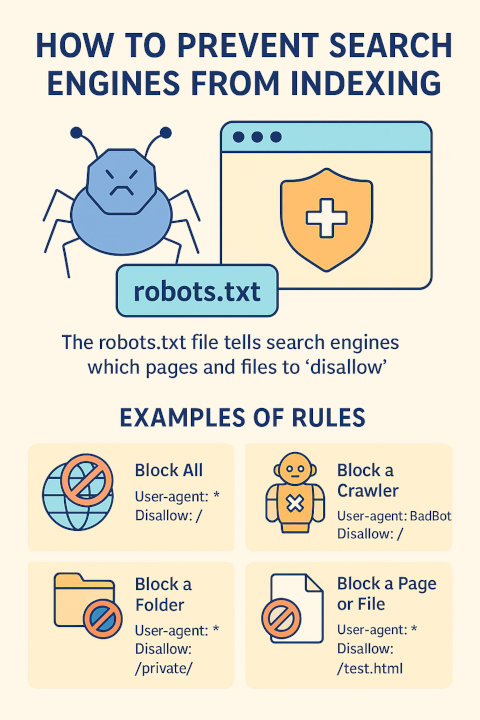
robots.txt Examples
Block All Bots from the Entire Website
This will prevent all search engines from accessing any part of your site:
User-agent: *
Disallow: /
Block a Specific Bot
If you want to block only a certain crawler, specify its user-agent as follows:
User-agent: BadBot
Disallow: /
Replace BadBot with the actual name of the bot you wish to restrict. You can find user-agent strings in bot documentation or server logs.
Block Certain Folders
To hide specific directories like image folders or admin panels, use:
User-agent: *
Disallow: /private/
Disallow: /img/
Block Individual Files
If you want to keep specific files hidden from search engines:
User-agent: *
Disallow: /downloads/secret.pdf
Disallow: /testpage.html
Important Notes on Using robots.txt
- robots.txt is public: Anyone or any bot/crawler can visit /robots.txt on your site and view/read its contents. It's not meant as a method for hiding sensitive data.
- Not foolproof: Some bots ignore the rules and will crawl your content anyway. Use password protection or HTTP authentication for sensitive content.
- Doesn't remove pages from search: If a page is already indexed, blocking it via robots.txt won't remove it from search results. Use the noindex meta tag instead (applied within the HTML).
Testing and Validating Your robots.txt
After setting up your robots.txt file, it's good practice to test it. Google offers a free robots.txt Tester in Search Console where you can verify if your rules are valid and being followed.
Common Mistakes to Avoid
- Incorrect placement: Make sure the file is in the root directory, not in a subfolder.
- Case sensitivity: URLs and paths in the file are case-sensitive on most servers.
- Syntax errors: Typos can render your rules ineffective. Always double-check your directives.
- Blocking important content: Avoid unintentionally blocking pages that contribute to SEO performance.
When You Should Not Use robots.txt
If your goal is to hide content completely, do not rely solely on robots.txt. Instead, use a more secure method like password protection, server permissions or a noindex meta tag. robots.txt simply advises bots what not to crawl; it doesn't enforce security.
Additional Resources
Search engine visibility is crucial for most websites, but not every page should be indexed. The robots.txt file gives you simple, centralized control over which areas of your site are available to search bots. Use it wisely to protect private content, streamline crawler activity and improve your site's SEO structure. Just remember, it's a guideline, not a barrier, and should be used alongside other best practices for complete control over your web presence.
More Server Tips
What is the Use of .ftpquota File? How to Install Apache HTTP Server on Windows How to Install Apache HTTP Server on Windows: The Apache Lounge Version Apache vs. Apache Lounge: Which One to Choose? How to Set FTP Quota for an FTP Account Apache Localhost Loading Very Slow: Here is the Solution How to Check If cURL is Enabled on Your Server
Server Tips